### Vector Displays
The Sketchpad, developed at MIT’s Lincoln Lab,...
Below you can see a picture of a a IBM 709 along with the included ...
The resulting line on the raster screen will be something like this...
The **Newton-Raphson** method is an iterative root-finding algorith...
This iterative method of finding square roots has been known since ...
Finding the square root of a number $V$ is equivalent to using Newt...
I think $G_n+1$ is a misprint for $G_{n+1}$.
Here is a simple implementation of the Bresenham’s algorithm in Jav...
### Floating Point Numbers
You can think of floating point numbe...
Given that $x$ is the fraction and $a$ is the characteristic:
$$\s...
In _Figure 3_ it would be better to say that the circle is circumsc...
There is a long history of computing more and more precise approxim...
Using a rapidly converging series:
$\pi = \sqrt{12}\left(1-\frac{1...
Professor John von Neumann was one of the people that expressed int...
### Modern computation of π
In the early 20th century the Indian m...
Of course the second identity immediately implies the first by sett...

The following three algorithms don’t have
much in common except for two things: They
were implemented between 1949 and 1965—
during the so-called first generation of comput-
ing hardware—and they are good examples of
rigorous thinking. First, I explain Bresenham’s
algorithm and apply it to a fundamental process
of computer graphics—drawing a line on a
raster screen. Second, although there are sever-
al ways to calculate a square root, the square
root algorithm is interesting because it takes
advantage of hardware design. And, finally,
while the calculation of π goes back more than
2,200 years, Machin’s algorithm from 1706 is of
importance to the history of computing.
Bresenham’s algorithm
Cathode-ray tube (CRT) displays for com-
puters were developed principally along two
lines, vector and raster, until the 1970s, when
memory became inexpensive. Initially, the
advantage of a vector display was that it could
draw a line by passing its end points to analog
circuitry, which moved an electron beam across
the CRT. To draw a line on a raster display, on
the other hand, required calculating the loca-
tions of every point that the line passed
through and illuminating each one.
Raster technology won out when it became
economically feasible to draw a display in a
dedicated memory and refresh the CRT from it.
Even though raster computation is more com-
plicated, vector display time varied with the
complexity of the diagram, making realistic
animation, for example, impossible.
In the 1950s, the IBM 704 and 709 comput-
ers included a CRT display with an addressable
raster of 1,024 × 1,024 dots. Once illuminated,
a dot would persist on the screen for about two
seconds. The CPU—excessively slow by today’s
standards—controlled the display, which had
no refresh buffer. The 704, for example, had a
12-microsecond cycle, meaning that the fastest
instruction executed in 24 microseconds.
Floating-point calculations were much slower;
a floating divide instruction took 18 cycles, or
216 microseconds.
Each dot was activated by the program’s
building a 36-bit word containing the X- and Y-
address of the dot, with the X-address in bits
8–17 and the Y-address in bits 26–35 and “copy-
ing” the word to the CRT (see Figure 1).
Obviously, the fastest way to refresh the screen
was to create a word for each illuminated dot
and to set up a “copy” loop. However, the maxi-
mum memory size for the 704 was 32,000 words,
including the program, so prestoring all the dots
wasn’t always feasible.
In actual use, the visible CRT was a “slave” to
another unit in a black box with a shutterless
35-mm camera. The general purpose of this
arrangement was to enable the camera to take a
picture of the master screen by illuminating dots
only once. Nevertheless, the process of calculat-
ing the positions of dots was so slow that only a
few dots could be displayed before the first one
began to fade. There was a demonstration pro-
gram—a tic-tac-toe game—for the display, and
even this simple picture flickered badly.
It was in this context, around 1960, that
computer scientist Jack Bresenham
1
consid-
ered how to minimize the calculation time for
the dots that make up a line. For a line with a
slope between 0 and 1, the Y-difference
between consecutive points on a straight line
is less than or equal to 1. For the line between
X1,Y1 and X2,Y2, such that 0 ≤∆Y ≤∆X and
X1 < X2, the X-addresses of the dots are X1,
X1 + 1, X1 + 2, … , X2. If ∆X = X2 – X1 and
∆Y = Y2 – Y1, then for each step in X, the val-
ues of Y are Y1, Y1 +∆Y/∆X, Y1 + 2∆Y/∆X, … ,Y2;
but raster point addresses are integers, so we
10 IEEE Annals of the History of Computing 1058-6180/02/$17.00 © 2002 IEEE
Three Early Algorithms
Keith S. Reid-Green
Three well-known algorithms, implemented separately within a span
of 20 years, demonstrate the use of mathematics developed
hundreds of years ago.
Figure 1. This 36-bit word activates a dot of a raster display.
S 1 2 3 4 5 6 7 8 9 1011121314151617181920212223242526272829303132333435
X-address Y-address

use Y1, int(Y1 +∆Y/∆X), int(Y1 + 2∆Y/∆X), and
so forth, without rounding.
In the following implementation of
Bresenham’s algorithm, Ratio and Delta are real
numbers; all other variables are integers. Note
that only addition and subtraction are used in
the For … Next loop.
DeltaX = X2 – X1
DeltaY = Y2 – Y1
Ratio = DeltaY / DeltaX
Delta = Ratio – 0.5
j = Y1
For i = X1 to X2
Call Dot (i, j)
If Delta > 0 Then
Delta = Delta – 1.0
j = j + 1
End If
Delta = Delta + Ratio
Next i
The For … Next loop is executed once per
dot, and so this part of the code should be
minimized. This loop would have taken about
60 cycles, or 720 microseconds. Because the
raster size of the master CRT was 3.366 × 3.366
inches, there were about 300 dots per inch.
Thus it took about 0.25 seconds to plot a line
one inch long. Note that the algorithm can be
improved by avoiding floating-point opera-
tions entirely:
DeltaX = X2 – X1´ All integer
variables
DeltaY = Y2 – Y1
Dy2 = 2 x DeltaY
Ratio = Dy2 – 2 x DeltaX
Delta = Dy2 – DeltaX
j = Y1
For i = X1 to X2
Call Dot (i, j)
If Delta > 0 Then
Delta = Delta + Ratio
j = j + 1
Else
Delta = Delta + Dy2
End If
Next i
This algorithm improves the loop’s speed by
about 15 percent.
Generalizing the algorithm to plot any line
requires determining which X-value is the
smaller, determining if the slope is ≤ 1 or > 1,
and requires using X or Y, respectively, as the
indexing value. A special case is if X1 = X2, but
this is easy to deal with.
A square root algorithm
From the very beginning of computing,
mathematical subroutines such as sine, cosine,
logarithm, A
X
, square root, and so on were avail-
able to programmers. The importance of opti-
mizing their speed is obvious because most
mathematical programs used them, and a single
program could call them thousands of times.
In the early days of minicomputers, hardware
costs were kept as low as possible so most mini-
computers did not have floating-point hard-
ware. Instead, floating-point operations were
accomplished in subroutines. At the same time,
functions like SQRT were done in software, so a
square root function with floating-point soft-
ware could be slow. The usual way to find a
square root was to use a Newton’s iteration:
where V is the value for which the square root
is to be found, and G1 is the first approxima-
tion (or first guess) of the square root. The cal-
culation is repeated until the difference
between G
n
+ 1 and G
n
is small enough, that is,
until G
2
n+1
is approximately equal to V.
Given that V can range over the set of posi-
tive numbers, a good first approximation of G
1
is not easy to find, and of course the better the
first guess, the faster the iteration converges.
However, for values of V less than 1, conver-
gence is fast.
Here’s where knowledge of the structure of
a floating-point number comes in handy. A
floating-point number mimics scientific nota-
tion—for example, we write 12.35 as 0.1235 ×
10
2
. The power of 10, called the characteristic, is
stored as a signed integer along with the frac-
tion and its sign. This structure suggests that we
can calculate the square root of the number by
dividing the characteristic by 2 and finding the
square root of the fraction.
Floating-point numbers are normalized, that
is, the first digit to the right of the point is
never zero (unless the value of the number is
zero). In a binary floating-point number, this
means that the first digit to the right of the
binary point is always a 1, thus the value of the
fraction is at least 0.5. So the square root of a
binary floating-point number 0.11000 … × 2
3
(in decimal, 6.0) can be found by halving the
characteristic and finding the square root of
0.11000 …, except that the characteristic is an
GG
GV
G
nn
n
n
+
=−
−
1
2
2
October–December 2002 11

odd number. This is easily remedied by adding
1 to the characteristic if it is odd and shifting
the fraction one place to the right, thereby
dividing it by two, yielding 0.011000 … × 2
4
, or
0.375 × 16—still 6.0. The square root of the
characteristic is 2
2
, and we can find the square
root of the fraction in four Newton’s iterations
to an error of not more than 0.000002, using
G
1
= 0.7. (It’s necessary to set the characteristic
to 2
0
so that the fraction V is between 0.25 and
1.) Furthermore, with a little effort, we can
determine a single calculation that develops
four iterations without a loop:
and
thus
and so on.
Finally, the resulting square root G
4
must be
multiplied by 10 to the power of the original
characteristic divided by 2, to yield the square
root of the original number V.
Machin’s algorithm; computation of π
The pursuit of more and more digits of π
may start with a reference in the Old
Testament,
2
to zero decimal places; that is, π=
3. The Babylonians got by nicely with π=3.125
(well, strictly speaking, 3 1/8, because decimal
fractions were unknown to the Babylonians).
The ancient Egyptians used π=4(8/9)
2
, which
is about 3.1605, not really any better than the
Babylonian estimate.
It was Archimedes (287–212 BCE) who start-
ed the contest of finding more and more digits
of π by inscribing and circumscribing a regular
polygon about a circle. This was a big step,
because it provided both an upper and a lower
bound for π, and the more sides to the polygon,
the tighter the bounds became. The area of a cir-
cle is πr
2
, so the area of a circle of unit radius is π.
For a hexagon, we see in Figure 2 that the
inscribed polygon consists of six equilateral
triangles with sides of length 1. Each has an
area of the square root of 3 divided by 4, so the
area of the inscribed hexagon is a bit more
than 2.598.
For a circumscribed hexagon (see Figure 3)
the height of each triangle is 1, so the area is
slightly greater than 0.57735, giving the area of
the circumscribed hexagon as about 3.4641.
Archimedes used these numbers to bound π.
He wrote the equivalent of
2.598 < π < 3.464
which suggests that π is about 3.03. This isn’t
very good, except that Archimedes went on to
use the same approach with 96-sided polygons
and refined his bounds to
3.14084 < π < 3.142858
although he had to use proper fractions:
3 10/71 < π < 3 1/7
This is more like it—the average of the
bounds is 3.14185; accurate to three decimals.
GG
GV
G
G
GV
G
V
G
GV
G
31
1
2
1
1
1
2
1
2
1
1
2
1
2
2
2
2
2
=−
−
−
−
−
−
−
GG
GV
G
32
2
2
2
2
=−
−
GG
GV
G
21
1
2
1
2
=−
−
12 IEEE Annals of the History of Computing
Three Early Algorithms
R=1
Figure 2. An inscribed hexagon decomposed into
six equilateral triangles.
R=1
Figure 3. A circumscribed hexagon.

For almost 2,000 years, refinements of π as cal-
culated in the Western world were done by
increasing the number of sides of the polygons.
Finally, with the advent of the calculus in
the 17th century came new ways to find π.
Notable was John Machin, a London professor
of astronomy, who in 1706 used the difference
between two arctangents. It was this method
that scientists used on ENIAC
3
in 1949 at the
University of Pennsylvania, setting a new
record of 2,037 digits:
π / 4 = 4 tan
– 1
(1/5) – tan
– 1
(1/239)
We know that π / 4 radians is 45 degrees, and
that the angle whose tangent is 1 is 45 degrees.
Unfortunately, we can’t calculate tan
– 1
(1) using
a series because the arctangent series only con-
verges for values less than 1—hence Machin’s
equation.
It is easy to test the equation:
Debug.Print 4# * (4# * Atn(1# / 5#) –
Atn(1# / 239#))
gives the result 3.14159265358979, exactly
right as far as it goes, but not a proof.
To show that
tan
– 1
(1) = 4 tan
– 1
(1/5) – tan
– 1
(1/239)
we need two trigonometric identities:
tan(2a) = (2 tan(a)) / (1 – tan
2
(a)) (1)
and
tan(a + b) = (tan(a) + tan(b)) / (1 – tan(a)
tan(b)) (2)
If we let x = atn(1/5), then using Equation 1 we
get
tan(2x) = (2 tan x) / (1 – tan
2
(x)) = 5/12
and
tan(4x) = (2 tan(2x)) / (1 – tan
2
(2x))
= 120/119
but we want the result to be 1. We can find the
difference from Equation 2:
tan(4x – π / 4) = (tan(4x) – 1) / (1 + tan(4x))
= 1/239
hence tan(4 atn(1/5) – atn(1/239)) resolves to 1.
Machin found
π / 4 to 100 places using two arc-
tangent series:
π / 4 = 4 (1/5 – 1 / (3 * 5
3
) + 1 / (5 * 5
5
) – …)
– (1/239 – 1 / (3 * 239
3
) + 1 / (5 * 239
5
) – …)
and this is how it was done on ENIAC to 2,037
places. Finding a very high precision result is a
nontrivial programming exercise, but that’s
another matter.
Acknowledgments
I would like to acknowledge the assistance of
Michael Greenwald, Dick Painter, and Dennis
Quardt in the preparation of this article.
References and notes
1. W.M. Newman and R.F. Sproull, Principles of Inter-
active Computer Graphics, 2nd ed., McGraw-Hill,
New York, 1979. Jack Bresenham is currently a
professor of computer science at Winthrop Uni-
versity. He retired from IBM as a senior technical
staff member in 1987 after 27 years. He is best
known for fast line and circle algorithms.
2. 1 Kings 23, Authorized (King James) Version.
The verse reads: “And he made a molten sea,
ten cubits from the one brim to the other: it
was round all about, and his height was five
cubits: and a line of thirty cubits did compass
it round about.” The “molten sea” is a brass
vat. Its diameter is ten cubits, thus its radius is
five cubits. The given circumference—the line
of 30 cubits that “did compass it round
about”—implies that π = 3, because the
circumference is computed as 2πr, from 2π * 5
= 30.
3. P. Beckmann, A History of Pi, Dorset Press, New
York, 1989.
Keith S. Reid-Green retired in
1999 after 42 years as a com-
puter scientist. He began as an
IBM 704 programmer in 1957
and is known for pioneering
work in data reduction, com-
puter-aided manufacturing,
and image processing. He is
widely published in the history of computing and
was an adjunct professor at the University of Utah
and at Rutgers, where he taught computer graphics
to graduate students. He holds bachelor’s degrees in
mathematics and physics and a master’s degree in
computer science.
Readers may contact Keith Reid-Green at 23 Point
Court, Lawrenceville, NJ 08648, email KReid-
Green@msn.com.
October–December 2002 13
Thanks Jadrian, I went ahead and corrected it.
This iterative method of finding square roots has been known since Babylonian times. This method is also known as Heron's method, after the first-century Greek mathematician Hero of Alexandria who gave the first explicit description of the method in his AD 60 work: Metrica.
Here is a simple implementation of the Bresenham’s algorithm in JavaScript.
```
let draw_line = (x0, y0, x1, y1) => {
// Calculate "deltas" of the line (difference between two ending points)
let dx = x1 - x0;
let dy = y1 - y0;
// Calculate the line equation based on deltas
let D = (2 * dy) - dx;
let y = y0;
// Draw the line based on arguments provided
for (let x = x0; x < x1; x++)
{
// Place pixel on the raster display
pixel(x, y);
if (D >= 0)
{
y = y + 1;
D = D - 2 * dx;
}
D = D + 2 * dy;
}
};
```
You can find a full tutorial along with an interactive demo [here](http://www.javascriptteacher.com/bresenham-line-drawing-algorithm.html)
I think $G_n+1$ is a misprint for $G_{n+1}$.
Of course the second identity immediately implies the first by setting b = a.
In _Figure 3_ it would be better to say that the circle is circumscribed by the hexagon. “A circumscribed hexagon” implies, rather, _Figure 2_ where the hexagon is circumscribed by a circle.
The resulting line on the raster screen will be something like this:

The basic intuition is that on each loop you have to decide whether you are increasing the $y$ coordinate by 1 or not.
### Modern computation of π
In the early 20th century the Indian mathematician Srinivasa Ramanujan found several rapidly converging infinite series of π, including:
$${\frac {1}{\pi }}={\frac {2{\sqrt {2}}}{9801}}\sum _{k=0}^{\infty }{\frac {(4k)!(1103+26390k)}{(k!)^{4}396^{4k}}}$$
This series computes a further eight decimal places of π with each term. Ramanujan series are the basis of a lot of the fastest algorithms used to compute Pi.
The current record was set in 2020 by Timothy Mullican, who computed 50 trillion digits of π. He wrote about it [here](https://blog.timothymullican.com/calculating-pi-my-attempt-breaking-pi-record)
Finding the square root of a number $V$ is equivalent to using Newton’s method to find the root of $f(x) = x^2 - V$. Newton’s method finds a root of $f(x)$ from a guess $x_n$ by approximating $f(x)$ as its tangent line at $x_n$ : $f(x_n) + f’(x_n)(x - x_n)$. To get $x_{n+1}$ you find the root of the tangent:
$$ f(x_n) + f’(x_n)(x - x_n) = 0$$
$$ f’(x_n)x = f’(x_n)x_n - f(x_n)$$
$$ x = x_n - \frac{f(x_n)}{f’(x_n)}$$
For $f(x) = x^2 - V$ you get:
$$x_{n+1} = x_n - \frac{x_n^2 - V}{2x_n}$$
### Vector Displays
The Sketchpad, developed at MIT’s Lincoln Lab, is an example of an early computer that made use of a vector displays.

### Raster Displays
Here is an example of a raster display - a slow motion recording of a CRT displaying Super Mario Bros. on a NES:

There is a long history of computing more and more precise approximations of π. Broadly you can divide it into 2 eras: before and after electronic digital computers.
Throughout the centuries many mathematicians worked on developing new methods of computing π. The 16th century German-Dutch mathematician Ludolph van Ceulen computed the first 35 decimal places of π with a 262 sided polygon. He was so proud of his achievement that he had the digits inscribed on his tombstone.

*Ludolph van Ceulen's tombstone*
The longest expansion of π before the advent of digital computing was achieved by the English amateur mathematician William Shanks in the late 19th century. He spent over 20 years calculating π to 527 places. To put it into perspective, in order to calculate the circumference of the the observable universe, 93 billion light-years in diameter, to a precision of less than one Planck length you need an approximation of π to 62 decimal places.
Given that $x$ is the fraction and $a$ is the characteristic:
$$\sqrt{x \times 10^a} \Leftrightarrow (x \times 10^a)^\frac{1}{2} \Leftrightarrow \sqrt{x} \times 10^\frac{a}{2}$$
The **Newton-Raphson** method is an iterative root-finding algorithm which produces successively better approximations to the zeroes of a real-valued function.
Here is a representation of a few iterations of the method
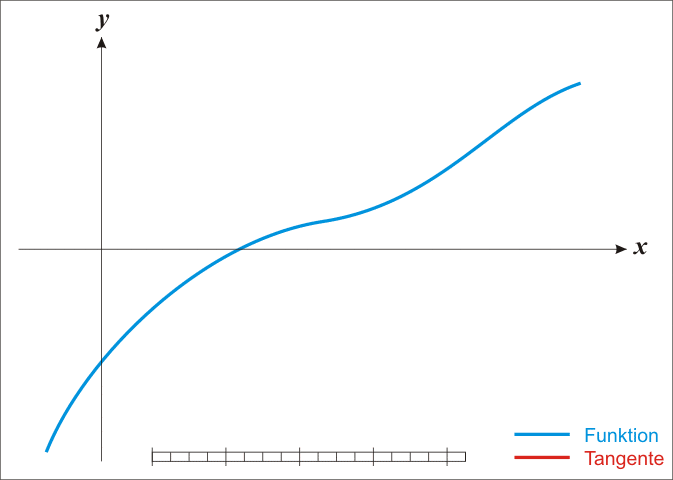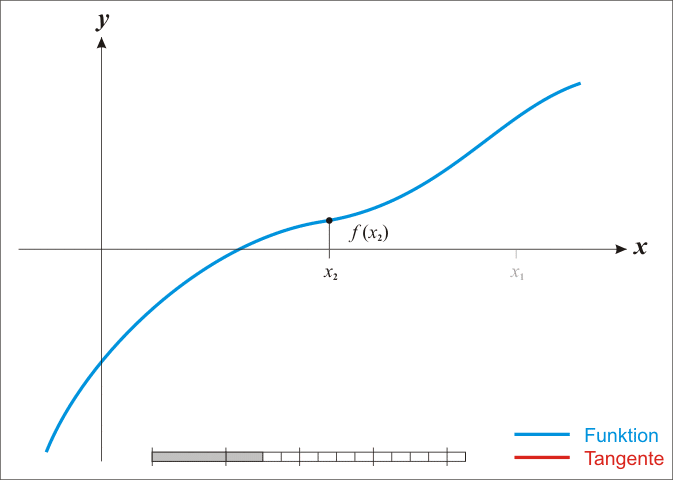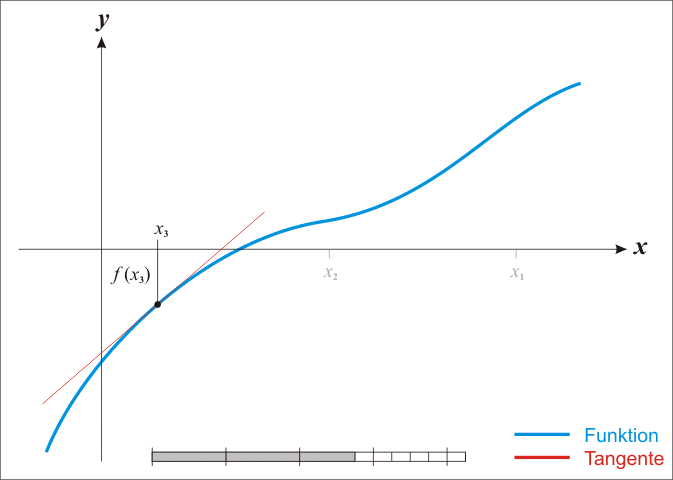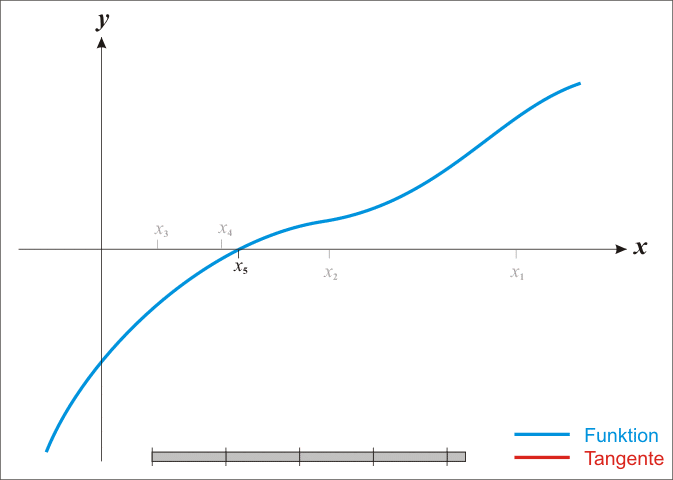
### Convergence
The **Newton-Raphson** method doesn’t always converge. Sometimes it can fail:
- Derivative may be zero at the root
- Function may fail to be continuously differentiable
- Choosing a bad starting point, i.e. one that lies outside the range of guaranteed convergence
It's Newton–*Raphson*; there's no *L* in Raphson's name.
Using a rapidly converging series:
$\pi = \sqrt{12}\left(1-\frac{1}{3.3}+\frac{1}{3.5^{2}}-\frac{1}{3.7^{2}}+\ldots \right)$
Madhava of Sangamagrama (Modern day Kerala, India) computed the the correct value of $\pi$ to 11 decimal digits as early as the period (c. 1340 – c. 1425) . The value of $\pi$ correct to 13 decimals, $\pi=3.1415926535898$, the most accurate since the 5th century, is sometimes attributed to Madhava.
https://en.wikipedia.org/wiki/Madhava_of_Sangamagrama
Professor John von Neumann was one of the people that expressed interest in having the ENIAC compute the value of π to many decimal places. Von Neumann was in fact interested in obtaining a statistical measure of the randomness of the distribution of the digits.
### Floating Point Numbers
You can think of floating point numbers as being written in *scientific notation*. A floating point number has 3 parts:
- **sign**: indicates whether the number is positive or negative
- **significant or fraction**: The significant digits of the number
- **exponent or characteristic**: indicates how large (or small) the number is
In the example below I’m using a biased exponent - which was popularized by the IBM 704. This was made a standard by the IEEE Standard for Floating-Point Arithmetic (IEEE 754). In this paper the author uses signed exponents.
Example
Let’s say we wanted to store `2019` as a floating point number:
- Decimal Representation: `2019`
- Binary Representation: `11111100011`
- Scientific notation: $ 2.019 \times 10^{3} $
- Binary Scientific notation: $1.1111100011 \times 2^{10}$
- Double Precision Raw Binary:

As you can see in the raw binary, the exponent is stored as `10000001001`, which is `1033`: `10` (the actual binary exponent) + `1023` (the bias, which allows you to store the exponent as an unsigned integer). This means that the exponent range is `−1022` to `+1023` (exponents of `−1023` (all 0s) and `+1024` (all 1s) are reserved for special numbers.)
Below you can see a picture of a a IBM 709 along with the included CRT display. The IBM 709 was an early vacuum tube powered computer introduced by IBM in 1958. The IBM 709 had 32,768 words of 36-bit memory, could execute 42,000 add instructions per second and could multiply two 36-bit integers at a rate of 5000 per second.
